1Z0-117 Online Practice Questions and Answers
Which two statements about In-Memory Parallel Execution are true?
A. It can be configured using the Database Resource Manager.
B. It increases the number of duplicate block images in the global buffer cache.
C. It requires setting PARALLEL_DEGREE_POLICY to LIMITED.
D. Objects selected for In-Memory Parallel Execution have blocks mapped to specific RAC instances.
E. It requires setting PARALLEL_DEGREE_POLICY to AUTO
F. Objects selected for In-Memory Parallel Execution must be partitioned tables or indexes.
You plan to bulk load data INSERT INTO . . . SELECT FROM statements.
Which two situations benefit from parallel INSERT operations on tables that have no materialized views defined on them?
A. Direct path insert of a million rows into a partitioned, index-organized table containing one million rows and a conventional B*tree secondary index.
B. Direct path insert of a million rows into a partitioned, index-organized table containing 10 rows and a bitmapped secondary index.
C. Direct path insert of 10 rows into a partitioned, index-organized table containing one million rows and conventional B* tree secondary index.
D. Direct path insert of 10 rows into a partitioned, index-organized table containing 10 rows and a bitmapped secondary index
E. Conventional path insert of a million rows into a nonpartitioned, heap-organized containing 10 rows and having a conventional B* tree index.
F. Conventional path insert of 10 rows into a nonpartitioned, heap-organized table one million rows and a bitmapped index.
Exhibit

Examine the following SQL statement:

Examine the exhibit to view the execution plan. Which statement is true about the execution plan?
A. The EXPLAIN PLAN generates the execution plan and stores it in c$SQL_PLAN after executing the query. Subsequent executions will use the same plan.
B. The EXPLAIN PLAN generates the execution plan and stores it in PLAN_TABLE without executing the query. Subsequent executions will always use the same plan.
C. The row with the ID 3 is the first step executed in the execution plan.
D. The row with the ID 0 is the first step executed in the execution plan.
E. The rows with the ID 3 and 4 are executed simultaneously.
Which three are tasks performed in the hard parse stage of a SQL statement executions?
A. Semantics of the SQL statement are checked.
B. The library cache is checked to find whether an existing statement has the same hash value.
C. The syntax of the SQL statement is checked.
D. Information about location, size, and data type is defined, which is required to store fetched values in variables.
E. Locks are acquired on the required objects.
Which two are the fastest methods for fetching a single row from a table based on an equality predicate?
A. Fast full index scan on an index created for a column with unique key
B. Index unique scan on an created for a column with unique key
C. Row fetch from a single table hash cluster
D. Index range scan on an index created from a column with primary key
E. Row fetch from a table using rowid
Examine the Exhibit and view the structure of an indexes for the EMPLOYEES table.
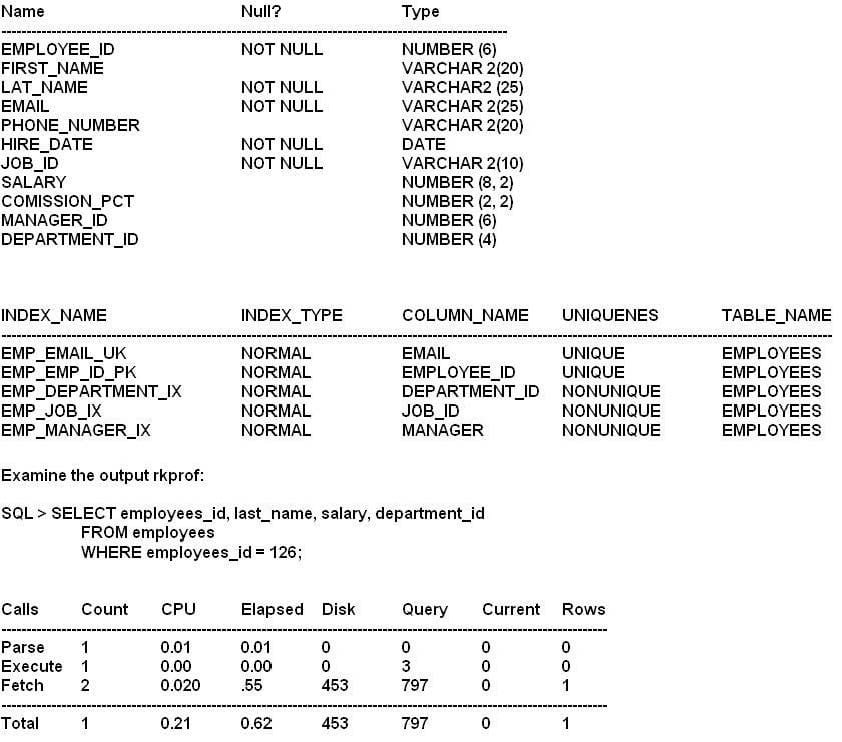
Which two actions might improve the performance of the query?
A. Use the ALL_ROWS hint in the query.
B. Collect the histogram statistics for the EMPLOYEE_ID column.
C. Decrease the value for the DB_FILE_MULTIBLOCK_READ_COUNT initialization parameter.
D. Decrease the index on the EMPLOYEE_ID if not being used.
E. Set the OPTIMIZER_MODE parameter to ALL_ROWS.
You need to migrate database from oracle Database 10g to 11g. You want the SQL workload to start the 10g plans in the 11g database instance and evolve better plans.
Examine the following steps:
1.
Capture the pre-Oracle Database 11g plans in a SQL Tuning Set (STS)
2.
Export the STS from the 10g system.
3.
Import the STS into Oracle Database 11g.
4.
Set the OPTIMIZER_FEATURES_ENABLE parameter to 10.2.0.
5.
Run SQL Performance Analyzer for the STS.
6.
Set the OPTIMIZER_FEATURES_ENABLE parameter to 11.2.0.
7.
Rerun the SQL Performance Analyzer for the STS.
8.
Set OPTIMIZER_CAPTURE_SQL_PLAN_BASELINE to TRUE.
9.
Use DBMS_SPM.EVOLVE_SQL_BASELINE function to evolve the plans.
10.
Set the OPTIMIZER_USE_SQL_PLAN_BASELINE to TRUE.
Identify the required steps in the correct order.
A. 1, 2, 3, 4, 5, 6, 7,
B. 4, 8, 10
C. 1, 2, 3, 4, 8, 10
D. 1, 2, 3, 6, 9, 5
E. 1, 2, 3, 5, 9, 10
You are administering a database supporting a DDS workload in which some tables are updated frequently but not queried often. You have SQL plan baseline for these tables and you do not want the automatic maintenance task to gather statistics for these tables regularly.
Which task would you perform to achieve this?
A. Set the INCREMENTAL statistic preference FALSE for these tables.
B. Set the STALE_PERCENT static preference to a higher value for these tables.
C. Set the GRANULARITY statistic preference to AUTO for these tables.
D. Set the PUBLISH statistic preference to TRUE for these tables.
Examine the exhibit.
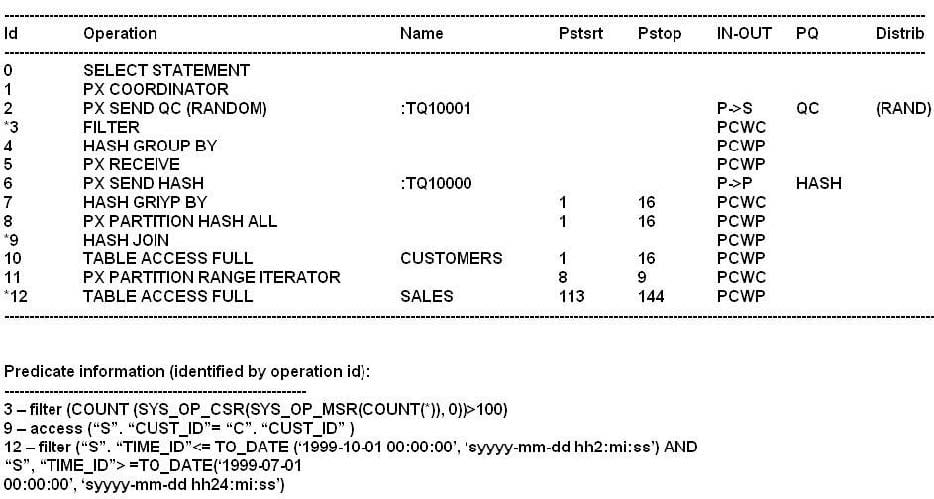
Which two are true concerning the execution plan?
A. No partition-wise join is used
B. A full partition-wise join is used
C. A partial partition-wise join is used
D. The SALES table is composite partitioned
Examine the Exhibit.

Which two statements are true about the bloom filter in the execution plan?
A. The bloom filter prevents all rows from table T1 that do not join T2 from being needlessly distributed.
B. The bloom filter prevents all rows from table T2 that do not join table T1 from being needlessly distributed.
C. The bloom filter prevents some rows from table T2 that do not join table T1 from being needlessly distributed.
D. The bloom filter is created in parallel by the set of parallel execution processes that scanned table T2.
E. The bloom filter is created in parallel by the set of parallel execution processes that later perform join.
F. The bloom filter is created in parallel by the set of parallel execution processes that scanned table T1.