70-762 Online Practice Questions and Answers
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
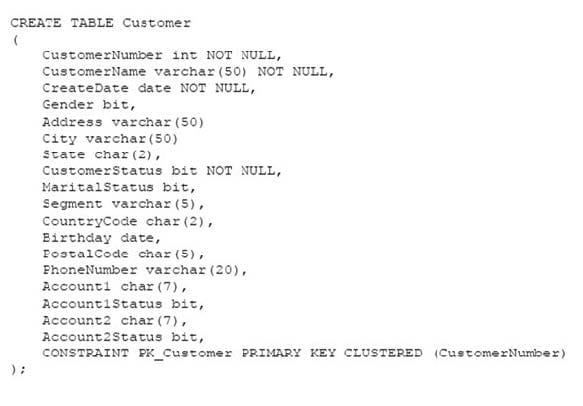
You have a database named DB1 that contains the following tables: Customer, CustomerToAccountBridge, and CustomerDetails. The three tables are part of the Sales schema. The database also contains a schema named Website. You create the Customer table by running the following Transact-SQL statement:

The value of the CustomerStatus column is equal to one for active customers. The value of the Account1Status and Account2Status columns are equal to one for active accounts. The following table displays selected columns and rows from the Customer table.

You plan to create a view named Website.Customer and a view named Sales.FemaleCustomers. Website.Customer must meet the following requirements:
1.
Allow users access to the CustomerName and CustomerNumber columns for active customers.
2.
Allow changes to the columns that the view references. Modified data must be visible through the view.
3.
Prevent the view from being published as part of Microsoft SQL Server replication. Sales.Female.Customers must meet the following requirements:
1.
Allow users access to the CustomerName, Address, City, State and PostalCode columns.
2.
Prevent changes to the columns that the view references.
3.
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary. The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:

You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
You must update the design of the Customer table to meet the following requirements.
1.
You must be able to store up to 50 accounts for each customer.
2.
Users must be able to retrieve customer information by supplying an account number.
3.
Users must be able to retrieve an account number by supplying customer information.
You need to implement the design changes while minimizing data redundancy.
What should you do?
A. Split the table into three separate tables. Include the AccountNumber and CustomerID columns in the first table. Include the CustomerName and Gender columns in the second table. Include the AccountStatus column in the third table.
B. Split the table into two separate tables. Include AccountNumber, CustomerID, CustomerName and Gender columns in the first table. Include the AccountNumber and AccountStatus columns in the second table.
C. Split the table into two separate tables, Include the CustomerID and AccountNumber columns in the first table. Include the AccountNumber, AccountStatus, CustomerName and Gender columns in the second table.
D. Split the table into two separate tables, Include the CustomerID, CustomerName and Gender columns in the first table. Include AccountNumber, AccountStatus and CustomerID columns in the second table.
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a database named DB1 that contains the following tables: Customer, CustomerToAccountBridge, and CustomerDetails. The three tables are part of the Sales schema. The database also contains a schema named Website. You create the Customer table by running the following Transact-SQL statement: The value of the CustomerStatus column is equal to one for active customers. The value of the Account1Status and Account2Status columns are equal to one for active accounts. The following table displays selected columns and rows from the Customer table.
You plan to create a view named Website.Customer and a view named Sales.FemaleCustomers.
Website.Customer must meet the following requirements:
Allow users access to the CustomerName and CustomerNumber columns for active customers.
Allow changes to the columns that the view references. Modified data must be visible through the view.
Prevent the view from being published as part of Microsoft SQL Server replication.
Sales.Female.Customers must meet the following requirements:
Allow users access to the CustomerName, Address, City, State and PostalCode columns.
Prevent changes to the columns that the view references.
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary. The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
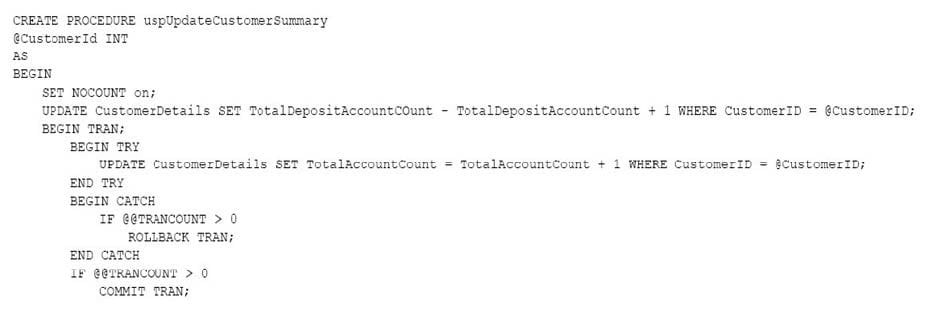
You run the uspUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
When you start uspUpdateCustomerSummary, there are no active transactions. The procedure fails at the second update statement due to a CHECK constraint violation on the TotalDepositAccountCount column.
What is the impact of the stored procedure on the CustomerDetails table?
A. A. The value of the TotalAccountCount column decreased.
B. The value of the TotalDepositAccountCount column is not changed.
C. The statement that modifies TotalDepositAccountCount is excluded from the transaction.
D. The value of the TotalAccountCount column is not changed.
E. The value of the TotalDepositAccountCount column is increased.
F. The statement that modifies TotalAccountCount column is excluded from the transaction.
G. The value of the TotalDepositAcountCount column is decreased.
Note: The question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other question in the series.
Information and details provided in a question apply only to that question.
You have a reporting database that includes a non-partitioned fact table named Fact_Sales. The table is persisted on disk.
Users report that their queries take a long time to complete. The system administrator reports that the table takes too much space in the database. You observe that there are no indexes defined on the table, and many columns have
repeating values.
You need to create the most efficient index on the table, minimize disk storage and improve reporting query performance.
What should you do?
A. Create a clustered index on the table.
B. Create a nonclustered index on the table.
C. Create a nonclustered filtered index on the table.
D. Create a clustered columnstore index on the table.
E. Create a nonclustered columnstore index on the table.
F. Create a hash index on the table.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some questions sets might have more than one correct solution,
while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a database that is 130 GB and contains 500 million rows of data.
Granular transactions and mass batch data imports change the database frequently throughout the day. Microsoft SQL Server Reporting Services (SSRS) uses the database to generate various reports by using several filters.
You discover that some reports time out before they complete.
You need to reduce the likelihood that the reports will time out.
Solution: You create a file group for the indexes and a file group for the data files. You store the files for each file group on separate disks.
Does this meet the goal?
A. Yes
B. No
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution. Determine whether the solution meets the stated goals. You have a table that has a clustered index and a nonclustered index. The indexes use different columns from the table. You have a query named Query1 that uses the nonclustered index. Users report that Query1 takes a long time to report results. You run Query1 and review the following statistics for an index seek operation:

You need to resolve the performance issue. Solution: You defragment both indexes. Does the solution meet the goal?
A. Yes
B. No
Background
You have a database named HR1 that includes a table named Employee.
You have several read-only, historical reports that contain regularly changing totals. The reports use multiple queries to estimate payroll expenses. The queries run concurrently. Users report that the payroll estimate reports do not always run. You must monitor the database to identify issues that prevent the reports from running.
You plan to deploy the application to a database server that supports other applications. You must minimize the amount of storage that the database requires.
Employee Table
You use the following Transact-SQL statements to create, configure, and populate the Employee table:

Application
You have an application that updates the Employees table. The application calls the following stored procedures simultaneously and asynchronously:
UspA: This stored procedure updates only the EmployeeStatus column.
UspB: This stored procedure updates only the EmployeePayRate column.
The application uses views to control access to data. Views must meet the following requirements:
Allow user access to all columns in the tables that the view accesses.
Restrict updates to only the rows that the view returns.
Exhibit

You are analyzing the performance of the database environment. You discover that locks that are held for a long period of time as the reports are generated.
You need to generate the reports more quickly. The database must not use additional resources.
What should you do?
A. Update all FROM clauses of the DML statements to use the IGNORE_CONSTRAINTS table hint.
B. Modify the report queries to use the UNION statement to combine the results of two or more queries.
C. Apply a nonclustered index to all tables used in the report queries.
D. Update the transaction level of the report query session to READ UNCOMMITTED.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some questions sets might have more than one correct solution,
while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a database that is 130 GB and contains 500 million rows of data.
Granular transactions and mass batch data imports change the database frequently throughout the day. Microsoft SQL Server Reporting Services (SSRS) uses the database to generate various reports by using several filters.
You discover that some reports time out before they complete.
You need to reduce the likelihood that the reports will time out.
Solution: You increase the number of log files for the database. You store the log files across multiple disks.
Does this meet the goal?
A. Yes
B. No
You have a relational data warehouse that contains 1 TB of data.
You have a stored procedure named usp_sp1 that generated an HTML fragment. The HTML fragment contains color and font style.
You need to return the HTML fragment.
What should you do?
A. Use the NOLOCK option.
B. Execute the DBCC UPDATEUSAGE statement.
C. Use the max worker threads option.
D. Use a table-valued parameter.
E. Set SET ALLOW_SNAPSHOT_ISOLATION to ON.
F. Set SET XACT_ABORT to ON.
G. Execute the ALTER TABLE T1 SET (LOCK_ESCALATION = AUTO); statement.
H. Use the OUTPUT parameters.
Note: This question is part of a series of questions that use the same or similar answer choices. An Answer choice may be correct for more than one question in the series. Each question independent of the other questions in this series.
Information and details provided in a question apply only to that question.
You are a database developer for a company. The company has a server that has multiple physical disks. The disks are not part of a RAID array. The server hosts three Microsoft SQL Server instances. There are many SQL jobs that run
during off-peak hours.
You must monitor and optimize the SQL Server to maximize throughput, response time, and overall SQL performance.
You need to examine delays in executed threads, including errors with queries and batches.
What should you do?
A. Create a sys.dm_os_waiting_tasks query.
B. Create a sys.dm_exec_sessions query.
C. Create a Performance Monitor Data Collector Set.
D. Create a sys.dm_os_memory_objects query.
E. Create a sp_configure `max server memory'query.
F. Create a SQL Profiler trace.
G. Create a sys.dm_os_wait_stats query.
H. Create an Extended Event.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You need to collect data from the following two sources:
1.
The performance counters of the operating system
2.
Microsoft SQL Server events
You must analyze the two datasets side-by side by using a single tool.
Solution: You use dynamic management views and Data Collector Sets (DCs) in Performance Monitor to collect performance data. You use SQL Server Management Studio (SSMS) to analyze the data.
Does this meet the goal?
A. Yes
B. No