DATABRICKS-MACHINE-LEARNING-ASSOCIATE Online Practice Questions and Answers
A data scientist wants to use Spark ML to one-hot encode the categorical features in their PySpark DataFramefeatures_df. A list of the names of the string columns is assigned to theinput_columnsvariable.
They have developed this code block to accomplish this task:

The code block is returning an error.
Which of the following adjustments does the data scientist need to make to accomplish this task?
A. They need to specify the method parameter to the OneHotEncoder.
B. They need to remove the line with the fit operation.
C. They need to use Stringlndexer prior to one-hot encodinq the features.
D. They need to useVectorAssemblerprior to one-hot encoding the features.
A data scientist has written a data cleaning notebook that utilizes the pandas library, but their colleague has suggested that they refactor their notebook to scale with big data.
Which of the following approaches can the data scientist take to spend the least amount of time refactoring their notebook to scale with big data?
A. They can refactor their notebook to process the data in parallel.
B. They can refactor their notebook to use the PySpark DataFrame API.
C. They can refactor their notebook to use the Scala Dataset API.
D. They can refactor their notebook to use Spark SQL.
E. They can refactor their notebook to utilize the pandas API on Spark.
A data scientist has been given an incomplete notebook from the data engineering team. The notebook uses a Spark DataFrame spark_df on which the data scientist needs to perform further feature engineering. Unfortunately, the data scientist has not yet learned the PySpark DataFrame API.
Which of the following blocks of code can the data scientist run to be able to use the pandas API on Spark?
A. import pyspark.pandas as ps df = ps.DataFrame(spark_df)
B. import pyspark.pandas as ps df = ps.to_pandas(spark_df)
C. spark_df.to_sql()
D. import pandas as pd df = pd.DataFrame(spark_df)
E. spark_df.to_pandas()
A data scientist has a Spark DataFrame spark_df. They want to create a new Spark DataFrame that contains only the rows from spark_df where the value in column price is greater than 0.
Which of the following code blocks will accomplish this task?
A. spark_df[spark_df["price"] > 0]
B. spark_df.filter(col("price") > 0)
C. SELECT * FROM spark_df WHERE price > 0
D. spark_df.loc[spark_df["price"] > 0,:]
E. spark_df.loc[:,spark_df["price"] > 0]
A data scientist wants to tune a set of hyperparameters for a machine learning model. They have wrapped a Spark ML model in the objective functionobjective_functionand they have defined the search spacesearch_space.
As a result, they have the following code block: Which of the following changes do they need to make to the above code block in order to accomplish the task?

A. Change SparkTrials() to Trials()
B. Reduce num_evals to be less than 10
C. Change fmin() to fmax()
D. Remove the trials=trials argument
E. Remove the algo=tpe.suggest argument
A machine learning engineer is converting a decision tree from sklearn to Spark ML. They notice that they are receiving different results despite all of their data and manually specified hyperparameter values being identical.
Which of the following describes a reason that the single-node sklearn decision tree and the Spark ML decision tree can differ?
A. Spark ML decision trees test every feature variable in the splitting algorithm
B. Spark ML decision trees automatically prune overfit trees
C. Spark ML decision trees test more split candidates in the splitting algorithm
D. Spark ML decision trees test a random sample of feature variables in the splitting algorithm
E. Spark ML decision trees test binned features values as representative split candidates
A data scientist has written a feature engineering notebook that utilizes the pandas library. As the size of the data processed by the notebook increases, the notebook's runtime is drastically increasing, but it is processing slowly as the size of the data included in the process increases.
Which of the following tools can the data scientist use to spend the least amount of time refactoring their notebook to scale with big data?
A. PySpark DataFrame API
B. pandas API on Spark
C. Spark SQL
D. Feature Store
Which of the following machine learning algorithms typically uses bagging?
A. Gradient boosted trees B. K-means
C. Random forest
D. Linear regression
E. Decision tree
A team is developing guidelines on when to use various evaluation metrics for classification problems. The team needs to provide input on when to use the F1 score over accuracy.
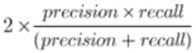
Which of the following suggestions should the team include in their guidelines?
A. The F1 score should be utilized over accuracy when the number of actual positive cases is identical to the number of actual negative cases.
B. The F1 score should be utilized over accuracy when there are greater than two classes in the target variable.
C. The F1 score should be utilized over accuracy when there is significant imbalance between positive and negative classes and avoiding false negatives is a priority.
D. The F1 score should be utilized over accuracy when identifying true positives and true negatives are equally important to the business problem.
A machine learning engineer is trying to scale a machine learning pipeline by distributing its feature engineering process.
Which of the following feature engineering tasks will be the least efficient to distribute?
A. One-hot encoding categorical features
B. Target encoding categorical features
C. Imputing missing feature values with the mean
D. Imputing missing feature values with the true median
E. Creating binary indicator features for missing values