DP-100 Online Practice Questions and Answers
DRAG DROP
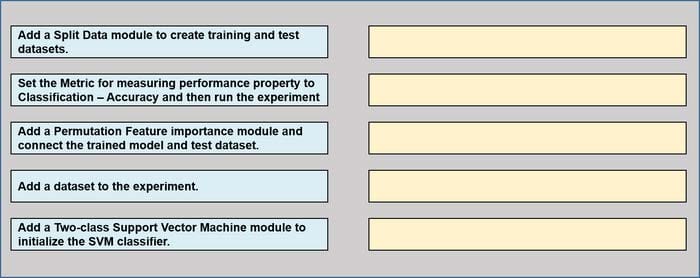
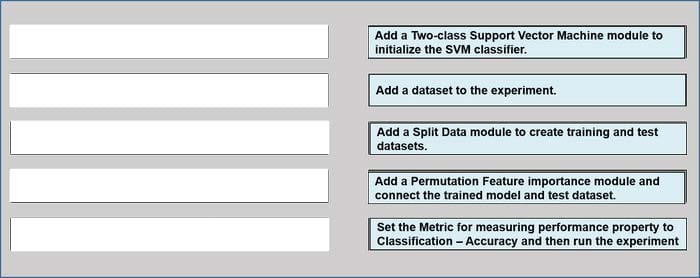
You have a dataset that contains over 150 features. You use the dataset to train a Support Vector Machine (SVM) binary classifier.
You need to use the Permutation Feature Importance module in Azure Machine Learning Studio to compute a set of feature importance scores for the dataset.
In which order should you perform the actions? To answer, move all actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
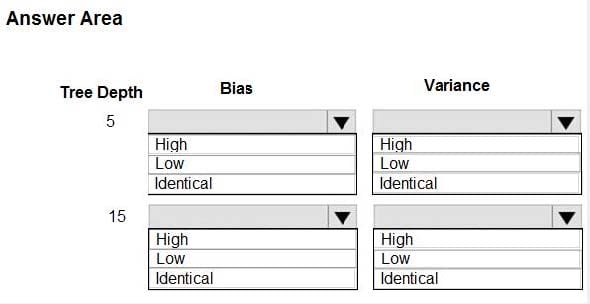
You are using a decision tree algorithm. You have trained a model that generalizes well at a tree depth equal to 10.
You need to select the bias and variance properties of the model with varying tree depth values.
Which properties should you select for each tree depth? To answer, select the appropriate options in the answer area.
Hot Area:

HOTSPOT
You have a multi-class image classification deep learning model that uses a set of labeled photographs. You create the following code to select hyperparameter values when training the model.

For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:


You plan to build a team data science environment. Data for training models in machine learning pipelines will be over 20 GB in size. You have the following requirements:
1.
Models must be built using Caffe2 or Chainer frameworks.
2.
Data scientists must be able to use a data science environment to build the machine learning pipelines and train models on their personal devices in both connected and disconnected network environments.
Personal devices must support updating machine learning pipelines when connected to a network.
You need to select a data science environment.
Which environment should you use?
A. Azure Machine Learning Service
B. Azure Machine Learning Studio
C. Azure Databricks
D. Azure Kubernetes Service (AKS)
You create a batch inference pipeline by using the Azure ML SDK. You configure the pipeline parameters by executing the following code:

You need to obtain the output from the pipeline execution. Where will you find the output?
A. the digit_identification.py script
B. the debug log
C. the Activity Log in the Azure portal for the Machine Learning workspace
D. the Inference Clusters tab in Machine Learning studio
E. a file named parallel_run_step.txt located in the output folder
You are a data scientist working for a bank and have used Azure ML to train and register a machine learning model that predicts whether a customer is likely to repay a loan.
You want to understand how your model is making selections and must be sure that the model does not violate government regulations such as denying loans based on where an applicant lives.
You need to determine the extent to which each feature in the customer data is influencing predictions.
What should you do?
A. Enable data drift monitoring for the model and its training dataset.
B. Score the model against some test data with known label values and use the results to calculate a confusion matrix.
C. Use the Hyperdrive library to test the model with multiple hyperparameter values.
D. Use the interpretability package to generate an explainer for the model.
E. Add tags to the model registration indicating the names of the features in the training dataset.
You are a lead data scientist for a project that tracks the health and migration of birds. You create a multi- class image classification deep learning model that uses a set of labeled bird photographs collected by experts. You have 100,000 photographs of birds. All photographs use the JPG format and are stored in an Azure blob container in an Azure subscription.
You need to access the bird photograph files in the Azure blob container from the Azure Machine Learning service workspace that will be used for deep learning model training. You must minimize data movement.
What should you do?
A. Create an Azure Data Lake store and move the bird photographs to the store.
B. Create an Azure Cosmos DB database and attach the Azure Blob containing bird photographs storage to the database.
C. Create and register a dataset by using TabularDataset class that references the Azure blob storage containing bird photographs.
D. Register the Azure blob storage containing the bird photographs as a datastore in Azure Machine Learning service.
E. Copy the bird photographs to the blob datastore that was created with your Azure Machine Learning service workspace.
You are preparing to train a regression model via automated machine learning. The data available to you has features with missing values, as well as categorical features with little discrete values.
You want to make sure that automated machine learning is configured as follows:
missing values must be automatically imputed.
categorical features must be encoded as part of the training task.
Which of the following actions should you take?
A. You should make use of the featurization parameter with the 'auto' value pair.
B. You should make use of the featurization parameter with the 'off' value pair.
C. You should make use of the featurization parameter with the 'on' value pair.
D. You should make use of the featurization parameter with the 'FeaturizationConfig' value pair.
You train and register a machine learning model. You create a batch inference pipeline that uses the model to generate predictions from multiple data files.
You must publish the batch inference pipeline as a service that can be scheduled to run every night.
You need to select an appropriate compute target for the inference service.
Which compute target should you use?
A. Azure Machine Learning compute instance
B. Azure Machine Learning compute cluster
C. Azure Kubernetes Service (AKS)-based inference cluster
D. Azure Container Instance (ACI) compute target
You are authoring a notebook in Azure Machine Learning studio.
You must install packages from the notebook into the currently running kernel. The installation must be limited to the currently running kernel only.
You need to install the packages.
Which magic function should you use?
A. !pip
B. %pip
C. !conda
D. %load